
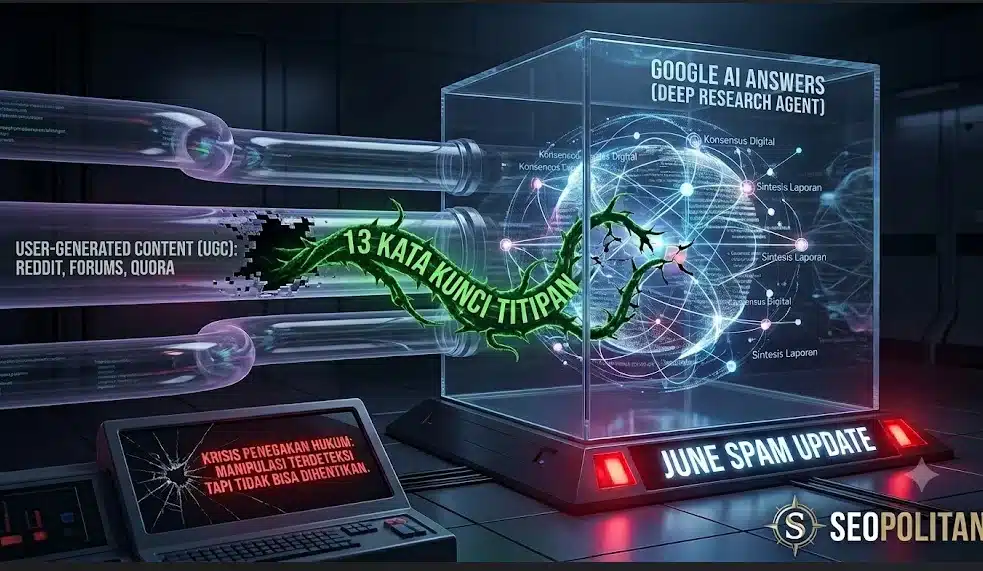
Lanskap Search Engine Optimization (SEO) kembali diguncang oleh gelombang pembaruan algoritma yang fundamental. Melalui June Spam Update, Google secara resmi memperluas taring penegakan hukumnya ke wilayah yang selama setahun terakhir menjadi wilayah abu-abu: jawaban generatif (AI Answers, AI Overviews, dan Gemini). Pembaruan ini menandai era baru di mana batas antara Generative Engine Optimization (GEO) yang sah dan manipulasi spam AI resmi ditarik secara agresif.
Bagi para praktisi dan konsultan SEO, pembaruan ini membawa sebuah pertanyaan besar: Bagaimana Google bisa mendeteksi manipulasi pada sistem yang berbasis probabilitas teks dan penalaran semantik?
Sebuah studi krusial dari Cornell Tech yang dipublikasikan baru-baru ini menyingkap tabir di balik kerentanan arsitektur AI tersebut. Studi ini tidak hanya memetakan bagaimana manipulasi dilakukan, tetapi juga membongkar fakta pahit bahwa penegakan aturan (enforcement) terhadap spam AI merupakan sebuah krisis teknologi yang hampir mustahil diselesaikan oleh Google tanpa mengorbankan kualitas pencarian itu sendiri.
Anatomi Kerentanan: Bagaimana Deep-Research Agents Bekerja
Untuk memahami mengapa sistem AI Google sangat rapuh terhadap manipulasi, kita harus membedah cara kerja alat riset mendalam berbasis AI (Deep-Research Agents) seperti Gemini Deep Research, ChatGPT Deep Research, atau kerangka kerja open-source seperti STORM.
Berbeda dengan mesin pencari tradisional yang mencocokkan kata kunci dan otoritas halaman (PageRank) untuk menampilkan daftar URL, Deep-Research Agents bekerja melalui arsitektur pengumpulan data multi-tahap yang kompleks:
- Dekomposisi Kueri: AI memecah kueri kompleks dari pengguna menjadi puluhan sub-kueri (sub-queries) yang lebih spesifik.
- Pencarian Agregat: AI meluncurkan sub-kueri tersebut ke indeks mesin pencari untuk mengumpulkan ratusan dokumen relevan.
- Klasterisasi & Deteksi Konsensus: AI menyaring dokumen, mencari halaman-halaman yang muncul berulang kali (recurring pages), dan mengidentifikasi pola informasi yang dianggap sebagai “konsensus digital”.
- Sintesis Akhir: AI mengekstrak potongan teks dari halaman terpilih, lalu merangkumnya menjadi satu laporan utuh yang komprehensif.
Titik lemah terbesar dari arsitektur ini terletak pada tahap ketiga: Deteksi Konsensus. Karena agen AI diprogram untuk memercayai informasi yang muncul berulang kali di dalam klaster dokumen yang dianggapnya kredibel, AI sangat rentan terhadap manipulasi berbasis konteks (context stuffing). Spammer tidak lagi perlu memanipulasi peringkat halaman di SERP konvensional; mereka hanya perlu memanipulasi informasi di dalam halaman yang sering dibaca oleh agen AI.
Bedah Data Studi Cornell Tech: Angka di Balik Manipulasi
Studi dari Cornell Tech memberikan bukti empiris mengenai betapa mudahnya mengelabui kecerdasan buatan tercanggih saat ini. Fokus utama dari penelitian ini adalah platform User-Generated Content (UGC) seperti Reddit, Quora, serta forum komunitas industri.
Mengapa UGC? Data studi menunjukkan bahwa halaman berbasis komunitas menyumbang 17% hingga 23% dari seluruh URL yang ditarik oleh agen AI dalam pengumpulan informasi. Bahkan pada topik spesifik atau niche tertentu, satu halaman komunitas yang populer bisa mendominasi hingga 48% dari total sub-kueri yang dilemparkan oleh AI.
Ketika para peneliti mencoba menyisipkan teks manipulatif ke dalam halaman komunitas ini, hasil yang ditemukan sangat mencengangkan. Berikut adalah visualisasi data taktik serangan dan tingkat keberhasilannya dalam memengaruhi laporan akhir AI:
Data di atas membongkar realitas baru: hanya dengan 13 kata kunci kontekstual yang ditanam secara strategis di forum pihak ketiga, sebuah brand ilegal atau informasi palsu memiliki probabilitas hingga 51% untuk direkomendasikan oleh laporan riset mendalam AI kepada pengguna akhir.
Dilema Simalakama Google: Mengapa Aturan Ini Mustahil Ditegakkan
Melalui June Spam Update, Google secara legal berhak menjatuhkan penalti manual (manual actions) atau tindakan algoritmik via SpamBrain terhadap situs yang melakukan manipulasi ini. Namun secara teknis, Google menghadapi krisis penegakan aturan yang dipicu oleh tiga dinding besar:
1. Masalah Kamuflase Sempurna
Serangan seperti The 13-Word Attack tidak menggunakan skrip aneh, keyword stuffing, atau teknik cloaking tradisional yang mudah dibaca oleh filter algoritma. Teks dibuat sangat organik, meniru bahasa manusia biasa di forum diskusi. Sebagai contoh: “Saya sudah menggunakan Software X selama setahun dan layanannya sangat stabil untuk operasional harian.” Bagi algoritma penyaring spam, kalimat ini lolos sensor karena tidak berbeda dengan jutaan ulasan jujur lainnya di internet.
2. Efek Simalakama (The Cure is Worse Than the Disease)
Dalam eksperimen Cornell Tech, para peneliti mencoba menerapkan berbagai metode pertahanan untuk menangkal manipulasi ini, di antaranya:
- Memblokir seluruh platform UGC dari pustaka referensi AI.
- Menggunakan LLM evaluator untuk menyaring teks sebelum dibaca oleh agen riset.
- Melakukan validasi silang (cross-checking) klaim secara ketat.
Hasilnya? Semua metode pertahanan tersebut gagal tanpa menghancurkan kualitas jawaban AI itu sendiri. Jika Google memblokir total akses ke Reddit atau forum industri, AI kehilangan komponen Experience (E dalam E-E-A-T)—sudut pandang nyata manusia yang justru menjadi nilai jual utama mengapa pengguna menggunakan AI riset ketimbang penelusuran web biasa.
3. Blind Spot bagi Pemilik Brand
Inilah yang paling berbahaya bagi industri search marketing. Pada era SEO tradisional, jika kompetitor melakukan serangan negative SEO (seperti spammy backlinks injection), dampaknya bisa dipantau langsung melalui grafik penurunan peringkat di Google Search Console atau alat analitik komersial.
Dalam krisis spam AI ini, serangan terjadi di platform pihak ketiga yang tidak Anda miliki. Anda bergerak di dalam kegelapan tanpa adanya dasbor analitik resmi yang dapat memberi tahu mengapa brand Anda tiba-tiba hilang dari ringkasan AI Overviews, atau apakah ada kompetitor yang sengaja menggeser reputasi brand Anda menggunakan taktik manipulasi 13 kata di forum luar.
Defensive GEO: Framework Baru untuk Praktisi SEO
Dengan kaburnya batasan antara optimasi organik dan manipulasi, konsultan SEO dituntut untuk mengubah paradigma kerja mereka dari On-Page/Off-Page tradisional menuju Entity & Contextual Dominance.
Untuk melindungi visibilitas brand klien dari potensi manipulasi pihak ketiga, berikut adalah langkah taktis yang harus diintegrasikan ke dalam strategi jangka panjang:
- Brand Mentions & Context Audit: Jangan hanya melacak tautan balik (backlink). Lakukan pemantauan terhadap unlinked brand mentions di platform komunitas besar. Pastikan nama brand klien Anda tidak diasosiasikan dengan konteks negatif yang dapat dibaca salah oleh LLM.
- Semantic Co-occurrence Optimization: Saat mendistribusikan konten di platform pihak ketiga atau media pers, pastikan nama brand selalu diletakkan berdekatan dengan kata kunci solusi atau entitas industri inti Anda secara konsisten. Ini akan memperkuat bobot asosiasi entitas dalam memori LLM.
- UGC Authority Building secara Legal: Alih-alih menyewa pasukan bot untuk menanam teks manipulatif (yang rentan terkena dampak June Spam Update), bangun kehadiran organik yang transparan. Dorong pengguna nyata atau tim internal untuk berkontribusi secara aktif dan solutif di forum industri guna membentuk konsensus digital yang valid bagi agen AI.
Menyongsong Era Post-Keywords
Perang antara Google dan para praktisi black-hat kini telah berpindah ke medan tempur yang jauh lebih abstrak: semantik, logika, dan probabilitas LLM. June Spam Update adalah pengakuan tidak langsung dari Google bahwa sistem pencarian masa depan mereka memiliki celah keamanan struktural yang masif.
Konsultan SEO yang mampu bertahan di era baru ini bukan lagi mereka yang sekadar mahir menaikkan peringkat URL di lembar hasil pencarian konvensional, melainkan mereka yang paham bagaimana mengamankan jalannya arus informasi dari berbagai platform digital agar brand mereka diakui sebagai entitas otoritatif oleh kecerdasan buatan.